Performance Comparison of AI Models for Image Shadow Removal: UNet, CGAN, and Swin-Transformer with a Note on Diffusion Models
Keywords:
Shadow Removal, UNet, Generative Adversarial Networks, Vision Transformer, Diffusion ModelsAbstract
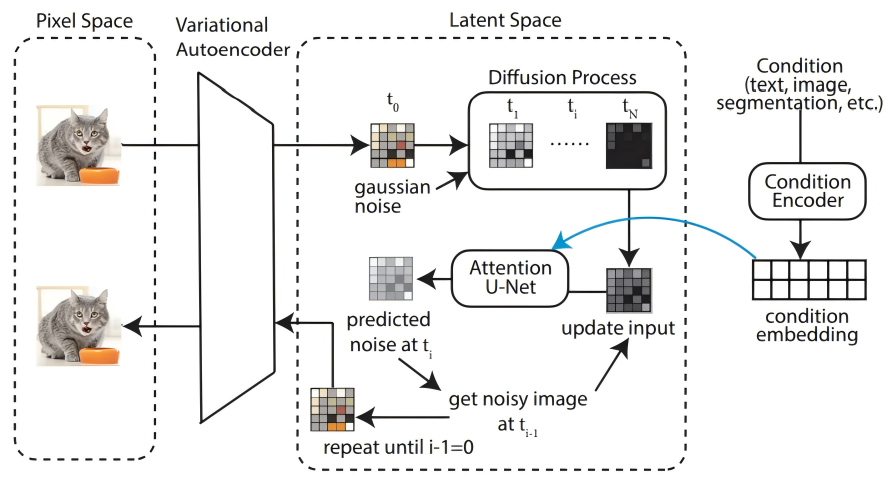
This study conducts a comprehensive performance comparison of three prominent deep learning architectures—UNet, Conditional Generative Adversarial Network (CGAN), and Swin-Transformer—for the task of single-image shadow removal, with additional theoretical consideration given to Denoising Diffusion Probabilistic Models (DDPM). Evaluated on the ISTD benchmark dataset using quantitative metrics (PSNR, SSIM, RMSE, MAE) and qualitative visual assessment, the results establish a clear performance hierarchy. The Swin-Transformer model consistently achieves superior results, excelling in detail preservation, artifact reduction, and maintaining global illumination consistency, attributed to its hierarchical structure and shifted-window self-attention mechanism. The CGAN model demonstrates enhanced perceptual realism through adversarial training, while the UNet provides a computationally efficient baseline. The findings offer practical guidance for model selection based on specific application requirements and highlight the impact of architectural design. This analysis concludes by suggesting future research pathways, including the exploration of hybrid models and the empirical application of diffusion models for high-fidelity image restoration tasks.
References
Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention (pp. 234-241). Cham: Springer
international publishing.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
Kinga, D., & Adam, J. B. (2015, May). A method for stochastic optimization. In International conference on learning representations (ICLR) (Vol. 5, No. 6).
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 10012-10022).
Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X., Tian, Q., & Wang, M. (2022, October). Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision (pp. 205-218). Cham: Springer Nature Switzerland.
Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision (pp. 2223-2232).
Wang, J., Li, X., Yang, J., & Lu, T. (2017). Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1788-1797).
Wang, J., Li, X., & Yang, J. (2018). Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1788-1797).
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E. L., ... & Norouzi, M. (2022). Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35, 36479-36494.
Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P. (2004). Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4), 600-612.
Ali, A. M., Benjdira, B., Koubaa, A., El-Shafai, W., Khan, Z., & Boulila, W. (2023). Vision transformers in image restoration: A survey. Sensors, 23(5), 2385.
Wang, W., Bao, J., Zhou, W., Chen, D., Chen, D., Yuan, L., & Li, H. (2022). Semantic image synthesis via diffusion models. arXiv preprint arXiv:2207.00050.