Parallel Firefly-Optimized Distributed Multiple Imputation for Scalable Education Data Preprocessing
Keywords:
Distributed Multiple Imputation, Firefly Optimization, Educational Data Mining, Graph PartitioningAbstract
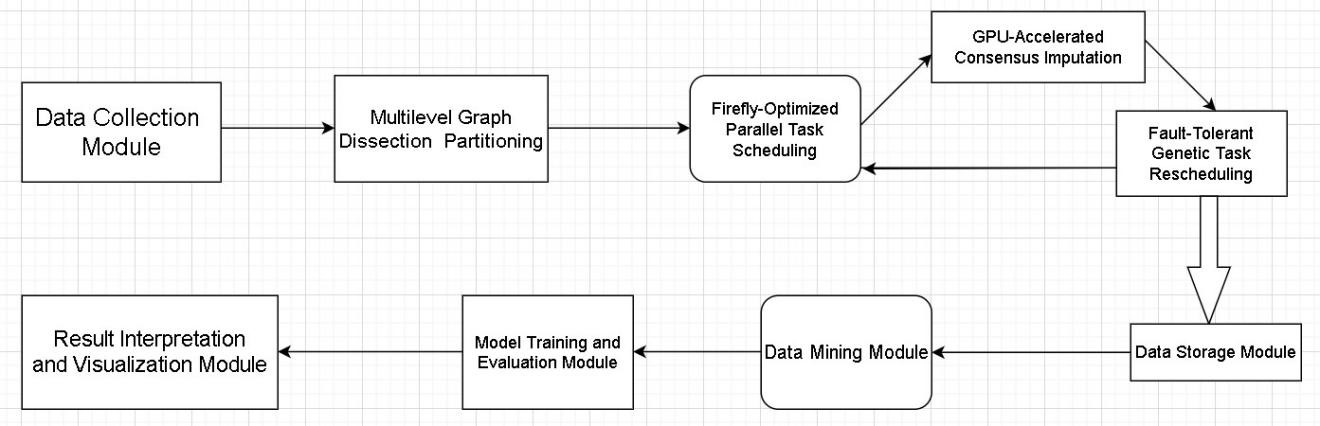
Missing data poses significant challenges in Educational Data Mining (EDM), where conventional multiple imputation (MI) methods often struggle with scalability and efficiency for high-dimensional datasets. We propose a novel Parallel Firefly-Optimized Distributed Multiple Imputation framework that integrates graph-based partitioning, bio-inspired load balancing, and GPU-accelerated consensus imputation to address these limitations. The system models education datasets as weighted graphs, partitioning them via multilevel dissection to minimize edge cuts while maintaining balanced workloads. A firefly algorithm dynamically schedules imputation tasks across distributed nodes, optimizing load distribution through decentralized attraction rules based on real-time node loads and network latency. Local imputation results are aggregated via a weighted consensus mechanism, ensuring robustness against node failures through a parallel genetic rescheduling strategy. The proposed method achieves linear scalability by combining graph theory, swarm intelligence, and parallel computing, outperforming centralized approaches in both speed and accuracy. Experimental validation on real-world EDM datasets demonstrates significant improvements in imputation efficiency, particularly for large-scale heterogeneous data. This work advances the state-of-the-art in scalable data preprocessing for EDM, offering a practical solution for modern educational analytics pipelines.